Giới thiệu
Trong bài viết trước Hướng dẫn cài đặt ELK stack trên CentOS 7, chúng ta đã cài đặt và cấu hình Filebeat gửi log đến Logstash. Trong bài viết hôm nay, chúng ta sẽ cùng cấu hình Logstash xử lý các dữ liệu nhận được từ Filebeat
Filebeat config
- Tạo sao dùng Logstash mà không đưa Input từ Filebeat trực tiếp vào Elastic và Kibana ?
Ở thời điểm mới ra mắt ELK stack, Logstash là công cụ thu thập log duy nhất và là nơi xử lý data nhận được thành structured data và dễ query hơn khi lưu vào Elasticsearch. Tuy nhiên, theo thời gian, Logstash gặp vấn đề về performance khi xử lý một khối lượng lớn lớn dữ liệu từ nhiều nguồn khác nhau. Filebeat ra đời để thay thế Logstash trong nhiệm vụ thu thập log, Filebeat nhẹ hơn Logstash nhiều lần đồng thời có thể đưa thằng log vào ES với data đã được chuẩn hóa cho từng dịch vụ mà Filebeat hỗ trợ. Tuy nhiên, Filebeat vẫn không có được khả năng Transformate dữ liệu và tách biệt các luồng dữ liệu khi có nhiều logging pipelines. Vậy nên nếu bạn cần xây dựng một hệ thống Centralized Logging, bạn vẫn sẽ cần tới Logstash 😀
Các bạn cần bổ sung thêm một “field” để Logstash có thể dựa vào đó mà xác định danh tính của một logging pipeline khi có nhiều Beat cùng đổ log vào một port 5044 của Logstash
filebeat.inputs: - input_type: log paths: - /var/log/nginx/access.log fields: custom_services: nginxlog fields_under_root: true
Với cấu hình trên, Output của Filebeat sẽ đính kèm thêm 1 Fields tên là “custom_services” và có giá trị là “nginxlog”, trong phần tiếp theo, chúng ta sẽ cấu hình Logstash dựa vào fields này để áp dụng filter đúng theo nhu cầu
Cấu hình Logstash
Phân loại các luồng dữ liệu bằng if
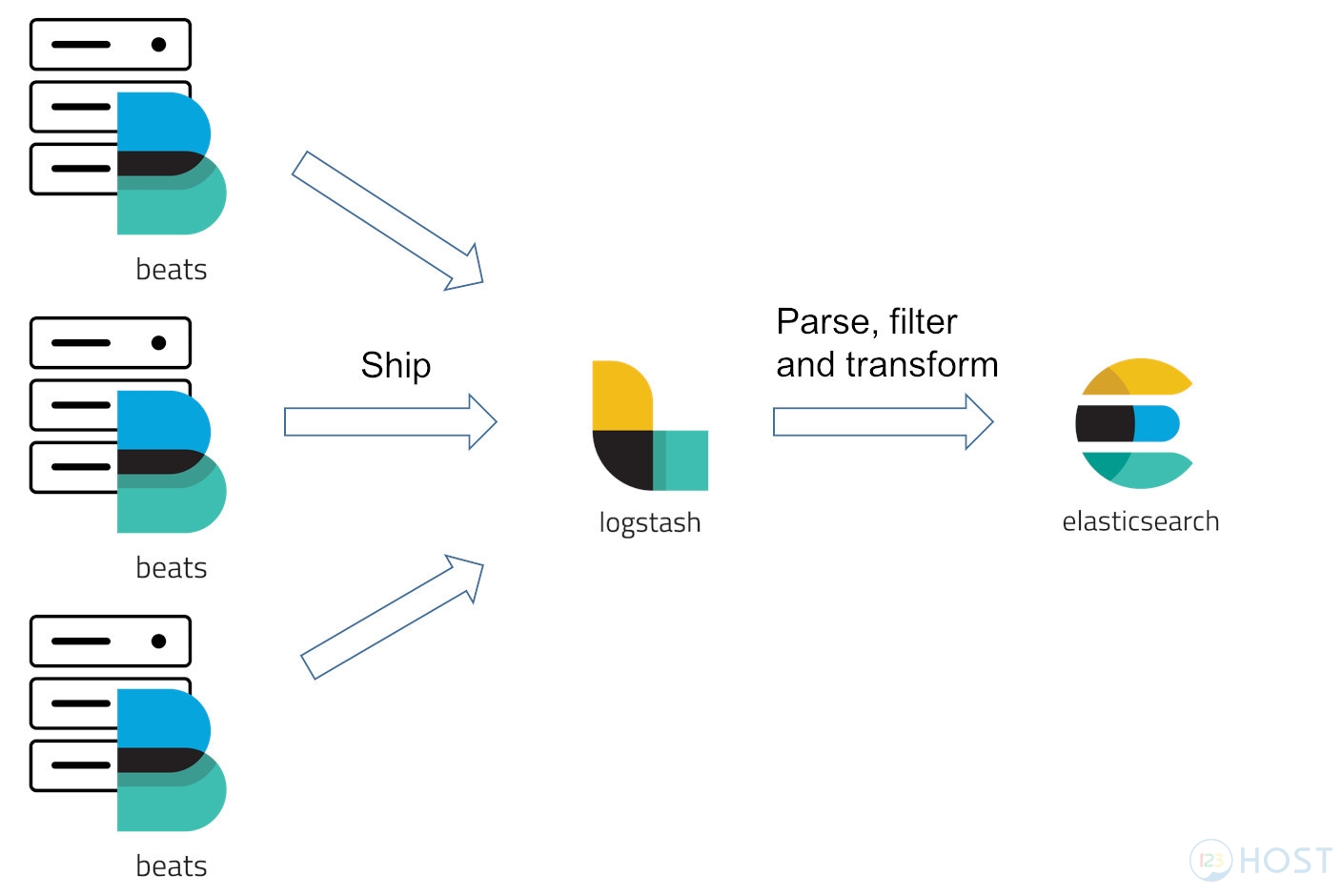
Như trong bài hướng dẫn trước, chúng ta đã hoàn thành 2 block “input” và “output”, tuy nhiên cấu hình trước chỉ để tham khảo và kiểm tra là các dịch vụ đã kết nối với nhau và hoạt động trơn tru. Các bạn sẽ giữ nguyên block “input” và thêm vào block filter như sau:
input { ........................ } filter { if [custom_services] == "nginxlog" { ........................ }
Nếu như luồng dữ liệu đưa vào Logstash match với cấu hình như trên, các Rules bên trong sẽ được áp dụng để xử lý luồng dữ liệu đó, nếu không match, toàn bộ dữ liệu sẽ forward tới output mà không thay đổi gì. Tiếp theo chúng ta sẽ cùng viết các rules để xử lý dữ liệu này.
Xử lý log sau khi phân loại
Grok – Unstructured log data into structured and queryable
Khi Filebeat gửi dữ liệu cho Logstash, giá trị của field “message” chỉ đơn thuần là một string như thế này
"message": "185.161.200.11 - - [04/Dec/2018:09:51:30 +0700] \"GET /manjaro/stable/multilib/x86_64/multilib.db HTTP/1.1\" 304 0 \"-\" \"pacman/5.1.1 (Linux x86_64) libalpm/11.0.1\""
Trước khi đưa vào Elasticsearch, chúng ta cần phải áp dụng một pattern lên string này để có thể tách biệt các giá trị và gán kiểu dữ liệu cho giá trị đó. Grok sẽ giúp chúng ta thực hiện việc này chỉ với một vài cấu hình đơn giản. Trước tiên chúng ta cần xem qua các pattern đã được định nghĩa sẵn trong file
/usr/share/logstash/vendor/bundle/jruby/2.3.0/gems/logstash-patterns-core-4.1.2/patterns/grok-patterns
Mở file này lên, các bạn sẽ thấy được các Pattern được định nghĩa sẵn và được phân loại theo nhóm, chúng ta sẽ thêm một pattern custom cho log của nginx – nginx combined.
NGINXACCESS %{IPORHOST:clientip} %{NGUSER:ident} %{NGUSER:auth} \[%{HTTPDATE:timestamp}\] "%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}" %{NUMBER:response} (?:%{NUMBER:bytes}|-) (?:"(?:%{URI:referrer}|-)"|%{QS:referrer}) %{QS:agent}Tiếp theo, chúng ta sẽ dùng grok để match các dữ liệu trong field “message” với pattern này
filter { if [custom_services] == "nginxlog" { grok { match => { "message" => "%{NGINXACCESS}" } }
Mutate – rename, remove, replace, and modify fields
Vì đây là pattern chung cho log nginx, vậy nên nếu bạn dùng lại pattern này cho nhiều log stream khác, bạn sẽ muốn rename các fields để phân biệt các luồng dữ liệu khác nhau, thực hiện rename bằng plugin mutate của Logstash
mutate { rename => { "clientip" => "nginx_remote_ip" "verb" => "nginx_method" "request" => "nginx_request_path" "response" => "nginx_response_staus" "bytes" => "nginx_body_sent" "agent" => "nginx_user_agent" } }
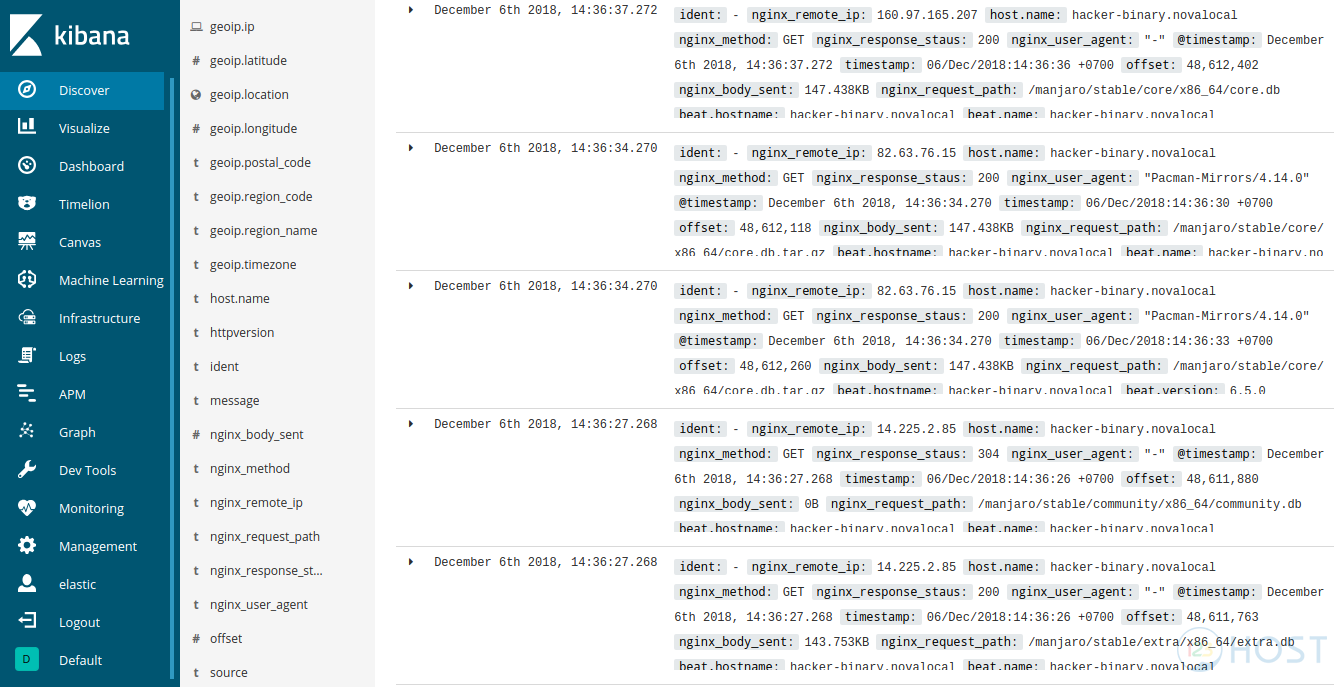
Sau khi rename, các fields sẽ hiển thị trong Kibana với tên mà bạn mong muốn

Plugin Mutate còn có rất nhiều function khác nhau, các bạn có thể tham khảo thêm tại đây
GeoIP – geographical location of IP addresses
GeoIP là một plugin khác của Logstash, cho phép chúng ta số hóa vị trí địa lý của User dựa trên Remote IP, GeoIP sẽ tự động lookup trên database có sẵn cho chúng ta kết quả vào output
geoip { source => "nginx_remote_ip" }
Chúng ta chỉ cần khai báo field chứa địa chỉ IP như trên là được
Output sử dụng template
Trước khi dữ liệu được đưa vào Elasticsearch, những fields khác nhau sẽ cần phải mapping với những type dữ liệu khác nhau để Kibana có thể áp dụng các dạng Visualize thích hợp lên dạng dữ liệu đó. Ví dụ như tọa độ trên bản đồ nếu để type là string thì Kibana không thể định vị được vị trí đó trên Global Map mà phải chuyển qua type “geo_point” hoặc như fields “nginx_body_sent” nếu để là type “text” thì không thể thực hiện tính tổng rồi hiển thị theo dạng dung lượng Megabytes, Gigabytes được…etc Vì thế chúng ta sẽ cần phải mapping các fields với type phù hợp với yêu cầu sử dụng.
Các bạn tạo file template /etc/logstash/elastic_logstash_default.json mới và thêm vào nội dung như sau
Điều chỉnh mapping trong file tempate. Trong file cấu hình template mặc định, mình đã mapping “nginx_body_sent” từ type “text” sang “integer”, các bạn có thể thêm mapping cho các fields khác nếu muốn.
"nginx_body_sent": { "type": "integer" }Cấu hình “output” của Logstash sử dụng template này như sau:
output { elasticsearch { hosts => ["http://localhost:9200"] index => "logstash-%{+YYYY.MM.dd}" codec => rubydebug template => "/etc/logstash/elastic_logstash_default.json" template_overwrite => true template_name => "elastic_logstash_default" } }
Toàn bộ file cấu hình của Logstash, các bạn có thể xem qua tại đây
Các bạn thực hiện restart Logstash và chờ cho đến khi Logstash khởi động hoàn tất, các bạn vào Kibana Dashboard và thêm Index mới cho Logstash
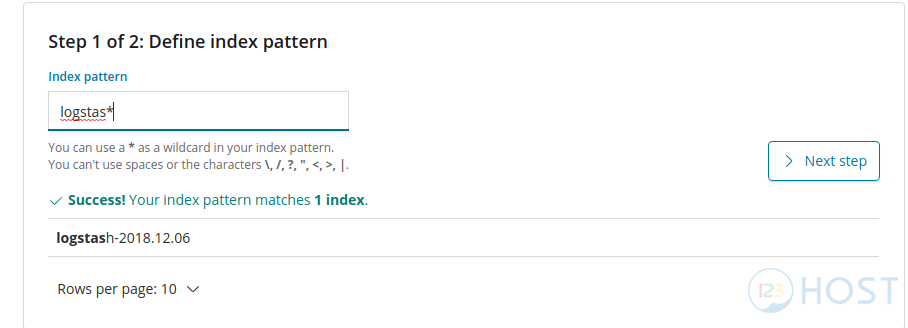
Sau khi tạo Index, các bạn vào lại Discover để xem các dữ liệu của bạn đã được filter như mong muốn chưa nhé
Kết luận
Như vậy là các bạn đã có thể nắm được các bước cơ bản để Transformate dữ liệu khi đi qua Logstash, Logstash còn rất nhiếu plugin và hỗ trợ rất nhiều dạng dữ liệu khác nhau, các bạn có thể tự nghiên cứu thêm và sử dụng đúng cho mục đích của mình. Trong các bài viết tiếp theo chúng ta sẽ cùng Visualize các dữ liệu này thành các biểu đồ với Kibana nhé, xin chào và hẹn gặp các bạn trong các bài viết sau.



Leave A Comment?