Chào các bạn,
Nội dung bài viết này mình sẽ giới thiệu đến các bạn về Kafka, một số thuật ngữ và cách thức hoạt động của Kafka.
Contents
Kafka là gì?
Kafka là một nền tảng truyền thông điệp (message) phân tán. Được LinkedIn phát triển để giải quyết những nhu cầu thực tế của hệ thống của họ.
Kafka xử lý hàng đợi theo cơ chế publish-subscribe, có hàng đợi mạnh mẽ có thể xử lý khối lượng dữ liệu lớn và cho phép bạn truyền thông điệp từ end-point này đến end-point khác. Các thông điệp của Kafka được lưu trữ trên disk và được nhân bản trong Cluster để tránh mất dữ liệu.
Lợi ích của Kafka
- Reliability: Kafka được phân tán (distribute), phân chia (partition), đồng bộ (replicate) và chịu lỗi (fault tolerance).
- Scalability: Kafka có thể mở rộng dễ dàng mà không bị downtime.
- Durability: Thông điệp được lưu trữ trên disk trong thời gian dài.
- Performance: Kafka có thông lượng cao trong cả publish-subscribe thông điệp. Nó duy trì được độ ổn định kể cả khi lưu trữ đến hàng TeraByte thông điệp.
Ứng dụng
- Quản lý log tập trung: Kafka có thể được sử dụng để thu thập log từ nhiều dịch vụ khác nhau và làm cho chúng luôn sẵn sàng để các consumer có thể đọc.
- Xử lý luồng: Các framework thông dụng như Storm, Spark đọc dữ liệu từ các topic, xử lý chúng và ghi dữ liệu đã xử lý vào một topic mới để cho người dùng và các ứng dụng khác sử dụng dữ liệu mới đó.
Thuật ngữ
Topic
Kafka gom các thông điệp cùng loại lại thành một danh mục gọi là topic. Ví dụ như log của apache được truyền đi vào kafka và đi ra sẽ được gom lại thành một topic để quản lý chung log của apache.
Partition
Là nơi lưu dữ liệu của topic. Mỗi topic có thể có một hay nhiều partition để có thể xử lý một lượng dữ liệu tùy ý.
Partition offset
Mỗi thông điệp được lưu trên partition sẽ được gán một giá trị theo thứ tự tăng dần gọi là offset. Có thể hiểu như đây là chỉ số của một mảng.
Replicas of partition
Là một bản backup của partition, chỉ được dùng để lưu trữ tránh mất dữ liệu, không được dùng để đọc ghi.
Broker
Là một Kafka Server. Nếu ta chạy đồng thời nhiều Kafka Server thì ta sẽ gọi đó là Cluster. Mỗi Broker (Kafka Server) sẽ là một node trong Cluster đó. Như vậy khi nói đến Broker, node thì ta sẽ hiểu đó là Kafka Server. Chịu trách nhiệm điều tiết thông điệp input output.
Partition sẽ nằm bên trong Broker. Một Broker có thể có 0 hoặc 1 hoặc nhiều partition đặt bên trong nó. Giả sử:
- 1 topic có N partition và trong Cluster có N Broker. Vậy thì mỗi Broker sẽ chứa 1 partition.
- 1 topic có N partition và trong Cluster có (N+M) Broker. Vậy thì N Broker đầu tiên, mỗi Broker sẽ chứa 1 partition. Còn M Broker còn lại sẽ không chứa partition nào của topic đó.
- 1 topic có N partition và trong Cluster có (N-M) Broker. Vậy thì mỗi Broker có thể có chứa nhiều hơn 1 partition. Kịch bản này không được khuyến nghị do sự phân tải không đồng đều giữa các Broker.
Producers
Procuder là ứng dụng truyền thông điệp đến cho Kafka Server (Broker, node) thông qua các topic. Khi Procuder truyền thông điệp đến Broker thì Broker sẽ đưa thông điệp đó vào cuối hàng đợi của 1 partition. Procuder có thể chọn gửi cho partition mong muốn.
Consumers
Consumer là ứng dụng đọc dữ liệu từ Broker thông qua các topic. Consumer có thể đọc dữ liệu từ 1 hoặc nhiều topic. Consumer có thể chọn đọc dữ liệu theo thứ tự mà nó muốn.
Leader
Mỗi partition sẽ có một Broker chịu trách nhiệm chính trong việc đọc và ghi dữ liệu vào partition đó. Broker đó sẽ được gọi là Leader.
Follower
Đây là một con replicas of partition. Khi có một Broker làm Leader thì các Broker còn lại trong Cluster sẽ là replicas of partition, nó sẽ làm Follower cho partition đó. Nó sẽ theo dõi Leader, nếu Leader bị die thì Zookeeper sẽ chịu trách nhiệm bầu ra 1 trong số các Follower lên làm Leader thay thế. Follower hoạt động giống như một Consumer, nhiệm vụ của nó là lấy dữ liệu từ Leader về lưu cho riêng nó.
Zookeeper
Được sử dụng để quản lý và điều phối các Kafka Broker.
- Zookeeper được sử dụng chủ yếu cho việc thông báo cho procuder và consumer biết thông tin của một broker mới thêm vào hoặc thông tin của một Kafka broker lỗi trong hệ thống Kafka.
- Sau mỗi thông báo của Zookeeper về việc broker thêm vào hay broker bị lỗi thì procuder và consumer sẽ quyết định và bắt đầu phối hợp với một broker khác.
Việc truyền tải dữ liệu giữa các hệ thống khác với Kafka broker được thực hiện thông qua giao thức TCP; việc phát triển, phân tích dữ liệu có thể thực hiện trên nhiều nền tảng ngôn ngữ lập trình khác nhau.
Cách thức hoạt động
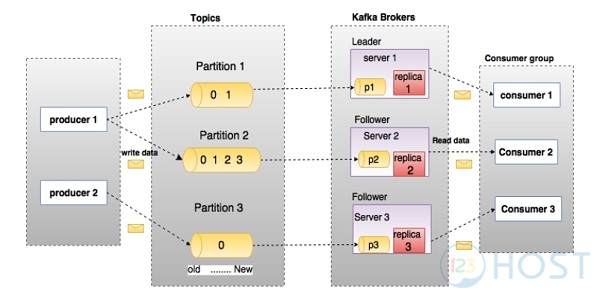
Nhìn vào hình trên ta sẽ thấy được cách mà Kafka hoạt động.
Khi Procuder gửi message đến Kafka thì Procuder sẽ gửi đến Kafka Server đang là Leader của partition thuộc topic của message đó. Những Kafka Server là Follower sẽ làm nhiệm vụ như một Consumer đi lấy message về lưu lại bản sao partition ở trên nó. Consumer cũng sẽ lấy message để sử dụng.
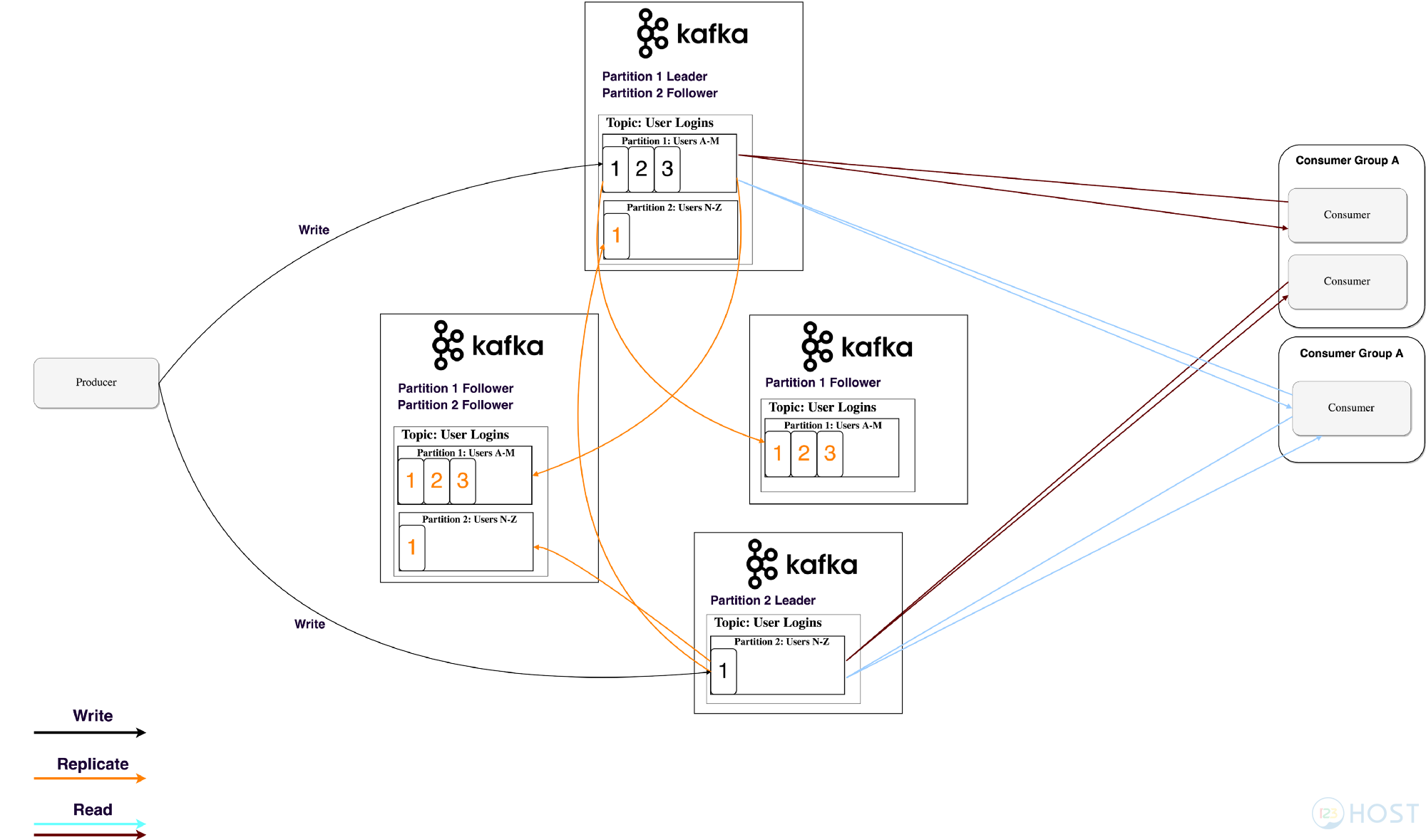
Ta thấy rằng kích thước của một topic có thể khá lớn nên chúng sẽ được chia ra thành các partition để dễ dàng xử lý và mở rộng hơn. (Ví dụ: giả sử bạn đang lưu trữ các yêu cầu đăng nhập của người dùng, bạn có thể chia chúng theo ký tự đầu tiên của tên người dùng của người dùng như ở hình trên).
Kafka đảm bảo rằng tất cả các message trong một partition sẽ được sắp xếp theo đúng thứ tự mà nó đi vào. Bạn sẽ phân biệt nó qua partition offset.
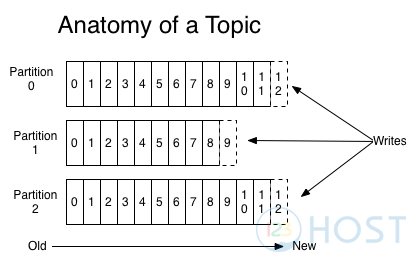
Kafka lưu toàn bộ các message trên partition trong thời gian dài hoặc theo ngưỡng lưu trữ (ví dụ đầy ổ cứng). Cho nên Kafka sẽ không cần quan tâm là Consumer đọc những gì, nhiệm vụ của nó là lưu thôi. Consumer sẽ tự đọc những gì mà nó muốn.
Cần lưu ý ở đây là Consumer thực sự là một nhóm các Consumer hoặc là một hay nhiều Consumer trong cùng 1 process. Do vậy, để tránh 2 các Consumer trong một group (hoặc là các Consumer trong chung một process) cùng xử lý một message đến hai lần thì Kafka quy định mỗi partition chỉ được đọc bởi một Consumer trong một group (hoặc là một Consumer trong nhiều Consumer trong một process).
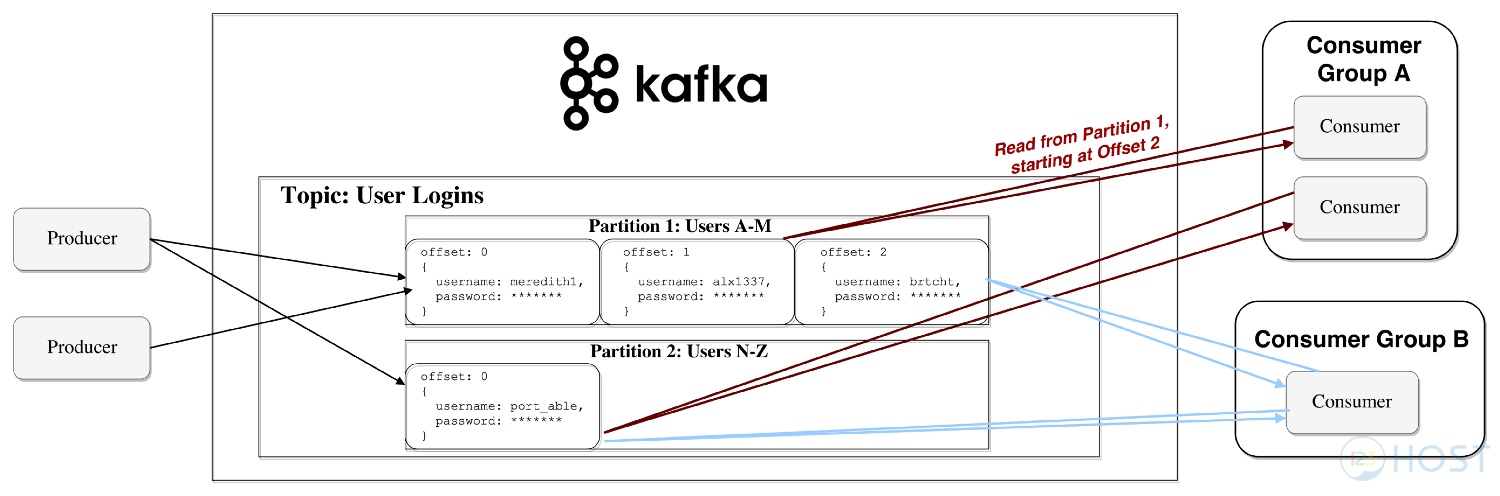
Giải thích rõ hơn ở chỗ này bằng ví dụ như sau:
- Giả sử có một group Consumer A và một topic B.
- Group Consumer A có A1, A2, A3. Topic B có partition B1, B2.
- Nếu chúng ta cho cả A1 và A2 cùng đọc B1 thì làm thế nào chúng ta đảm bảo rằng A1 và A2 không cùng xử lý chung một message thuộc B1? Giải pháp có thể là xóa message sau khi đọc xong hoặc là set trạng thái message đã được đọc. Cả hai giải pháp này đều không hiệu quả. Sẽ tốn thêm nhiều việc phải xử lý. Trong khi đó Kafka được thiết kế để xử lý khối lượng dữ liệu lớn.
- Thêm nữa Kafka đảm bảo các message trong một partition được xử lý theo đúng thứ tự nó đến.
- Giả sử B1 có 2 message theo thứ tự là b1 và b2. Giờ cả A1 và A2 cùng đọc B1. A1 đọc b1 trước, giả sử b1 tốn 1 khoảng thời gian rất dài để xử lý. Nếu b2 chỉ tốn một khoảng thời gian ngắn để xử lý và A2 đọc b2 thì b2 sẽ được xử lý trước b1. Như vậy sẽ không đúng như bảo đảm trước đó. Như vậy sẽ cần có giải pháp đồng bộ hóa để A2 chờ A1 xử lý xong b1 rồi A2 mới xử lý b2. Vậy là thời gian để A2 đợi là lãng phí. Và chỉ làm hệ thống thêm phức tạp.
Tóm lại ở đây thì một Consumer có thể đọc nhiều partition. Nhưng một partition chỉ được bởi một Consumer duy nhất thuộc một group.
Trở lại với cách thức hoạt động của Kafka ở trên kia, phát sinh vấn đề là làm thế nào để Procuder biết ai là Leader để gửi message đến?
Ta sẽ xem hình dưới:
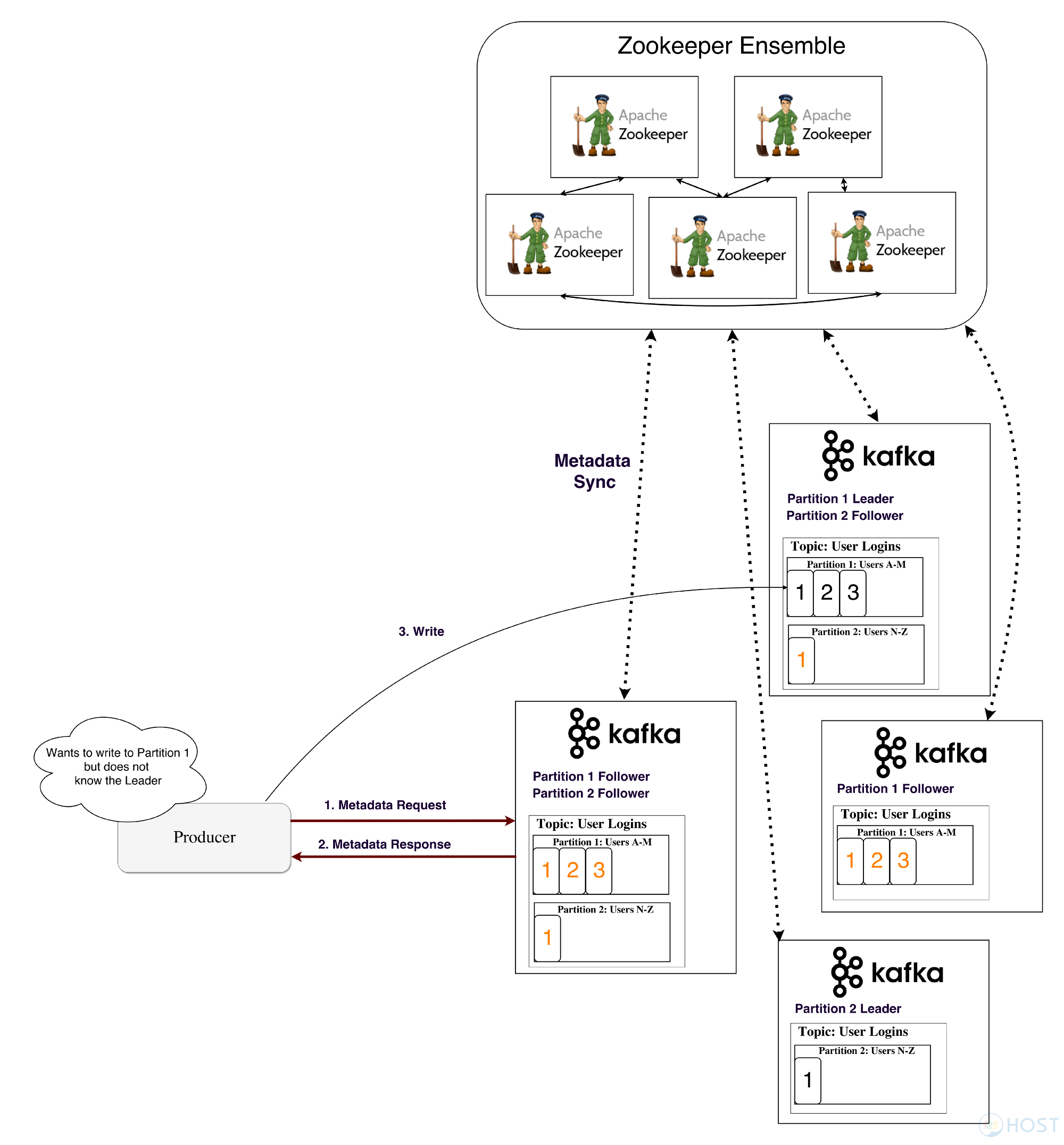
Nhờ có Zookeeper mà vẫn đề trên đã được giải quyết. Procuder sẽ gửi một truy vấn đến một Kafka Server bất kì mà nó biết để hỏi xem ai là Leader. Trên Kafka Server bất kì kia trước đó đã giao tiếp với Zookeeper nên nó biết ai là Leader, Kafka Server bất kì này mới trả lời lại cho Procuder kết quả và Procuder sẽ gửi message đến đúng Leader. (Ở các phiên bản cũ từ 0.8 trở về trước thì Procuder và Consumer nói chuyện trực tiếp với Zookeeper, còn từ phiên bản 0.9 trở đi thì như vừa mô tả)
Vậy là đã xong phần giới thiệu và cách thức hoạt động của Kafka, mong rằng bài viết sẽ giúp các bạn hiểu hơn về Kafka.
Các bạn có thể xem bài hướng dẫn cài đặt Kafka ở đây.
Thân!
Bài hướng tham khảo từ nhiều nguồn: TutorialSpoint, HackerMoon.



Leave A Comment?